
AWS Backup Recovery Pipeline - Consulta histórica de backups MySQL
Este proyecto transforma un proceso manual y lento de recuperación de datos históricos en un
pipeline reproducible en AWS. A partir de backups MySQL comprimidos en formato
.sql.gz, la solución genera datasets Parquet consultables desde
Athena, con trazabilidad operativa, catalogación en Glue y
despliegue reusable mediante Terraform.
Problema real
Cuando un equipo necesita revisar un backup antiguo, el flujo suele ser demasiado manual: localizar el dump, descargarlo, restaurarlo en local o en una instancia temporal y buscar los registros a mano. Si hace falta comparar otra fecha o revisar otro tenant, el proceso vuelve a empezar.
Ese enfoque resuelve urgencias, pero no escala bien. Consume tiempo, depende del entorno de un developer y deja poca trazabilidad sobre qué se procesó y con qué resultado.
Solución aplicada
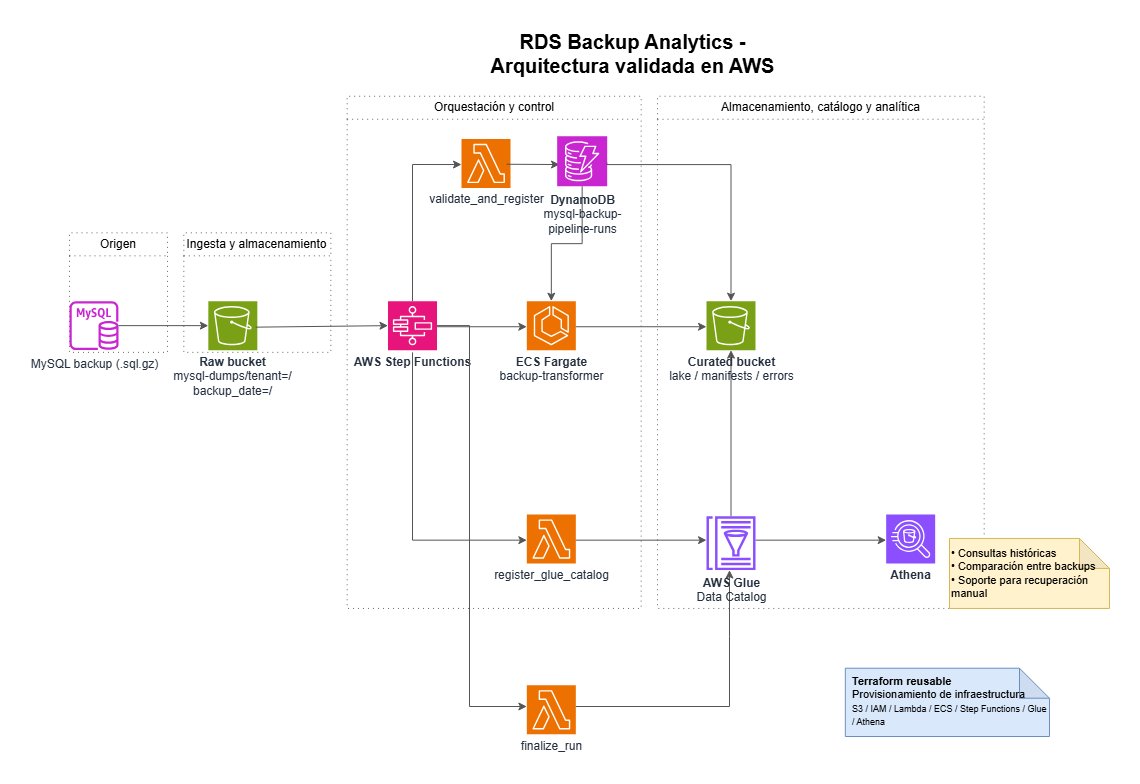
La arquitectura final preserva el dump original en S3 raw y lo transforma bajo demanda a una capa analítica en Parquet. La ejecución se orquesta con Step Functions, usa Lambda para validación y catalogación, y delega el trabajo pesado de parseo y escritura a ECS Fargate.
- El backup MySQL `.sql.gz` entra en S3.
- Step Functions valida la entrada y genera `run_id`.
- Fargate descomprime, parsea el SQL y escribe tablas en Parquet.
- Glue registra tablas y particiones.
- Athena consulta los datos por `tenant` y `backup_date`.
Decisiones técnicas clave
- El dump original se conserva intacto en `raw` como fuente de verdad.
- La salida final es Parquet para reducir escaneo y mejorar eficiencia en Athena.
- Fargate actúa como motor de transformación porque el parseo y la escritura exceden el caso de uso cómodo de una Lambda única.
- Glue se registra de forma explícita para controlar mejor tablas, particiones y trazabilidad.
- Terraform replica el flujo validado para dejar una versión reusable de la arquitectura.
Validación real en AWS
El proyecto no se quedó en una idea o una maqueta de infraestructura. El MVP se validó en una cuenta AWS real procesando un backup MySQL comprimido y confirmando el comportamiento del flujo de extremo a extremo.
- Se procesó un backup `.sql.gz` real.
- Se generaron datasets Parquet en la capa curated.
- Se escribió `manifest.json` como evidencia operativa.
- Glue creó correctamente tablas y particiones.
- Athena devolvió resultados válidos sobre los datos procesados.
Valor del proyecto
Este caso resume bien el tipo de trabajo que más me interesa: convertir una necesidad operativa real en una solución reproducible, observable y con criterio de arquitectura. No busca cubrir todos los escenarios posibles de restauración, sino resolver con claridad uno muy concreto: consultar histórico desde backups sin restaurar bases completas.
Trade-offs y limitaciones
- El parser MVP se centra en `CREATE TABLE` e `INSERT INTO ... VALUES`.
- Algunos tipos pueden degradarse a `string` en el catálogo analítico.
- Backups con SQL exótico o BLOBs requieren hardening adicional.
- La reinserción automática en MySQL origen queda fuera del alcance actual.
¿Quieres revisar la arquitectura completa o adaptar este enfoque?
El repositorio público incluye código, Terraform, diagramas y documentación técnica del flujo validado.
Ver repositorio en GitHub -> Comentar un caso similar