
Diseñar alertas preventivas en AWS con Terraform: enfoque IaC y rollout seguro
Introducción
Cuando un equipo decide mejorar su observabilidad, el error habitual no es elegir mal una métrica. El error habitual es convertir la monitorización en una lista de checks manuales, sin versionado, sin trazabilidad y sin un flujo claro de despliegue.
Para evitar ese problema, una estrategia eficaz es tratar las alertas como infraestructura como código (IaC): recursos versionados, revisables y desplegables con el mismo rigor que el resto de la plataforma.
Este artículo no se centra en comandos concretos. Se centra en como diseñar un sistema de alertas preventivas en AWS con Terraform para que sea:
- Repetible entre entornos.
- Revisable en Pull Request.
- Seguro de desplegar.
- Fácil de evolucionar.
Si buscas la implementación paso a paso con recursos y ejemplos Terraform, revisa el artículo complementario: Implementar alarmas de infraestructura con Terraform en AWS (SNS + CloudWatch) paso a paso.
Por que IaC para alertas (y no solo consola)
Crear alarmas desde consola AWS puede ser correcto para aprender el flujo o validar una hipotesis. De hecho, es una muy buena forma de entender la evaluación visual de CloudWatch.
El problema aparece cuando necesitas mantener el sistema:
- nuevos entornos (
dev,staging,prod) - cambios de thresholds
- nuevos canales de notificación
- auditoría de quien cambio que
Con IaC, la conversación cambia:
- El cambio queda en código.
- Se revisa en PR.
- Se valida con
plan. - Se despliega con
apply.
Y, sobre todo, se puede replicar.
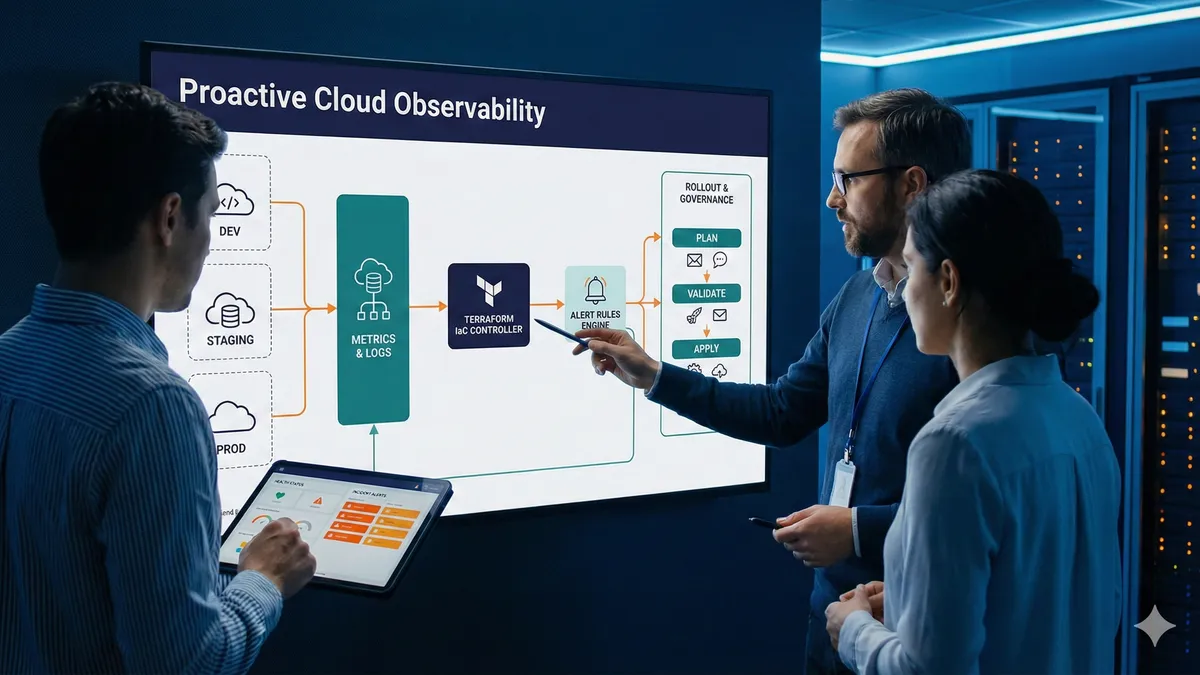
Arquitectura mínima que escala bien
Para un baseline de alertas preventivas, no necesitas una arquitectura compleja. Una composición simple cubre mucho terreno:
- Métricas nativas (por ejemplo,
AWS/EC2). - CloudWatch Alarms para evaluación de umbrales.
- SNS como capa de notificación desacoplada.
Esta separación es importante:
- CloudWatch evalua.
- SNS distribuye.
- Tu equipo decide después si consume por email, Slack, Chatbot o incident management.
Principios de diseño recomendados
1) Empezar por alertas preventivas, no por volumen
Es mejor desplegar pocas alertas bien calibradas que muchas alertas ruidosas.
Ejemplo de baseline EC2:
CPU warningCPU criticalStatusCheckFailedCPUCreditBalance(si la instancia es burstable)
Esto ya te da cobertura operativa real sin saturar al equipo.
2) Estandarizar naming desde el inicio
Un patrón de nombres consistente reduce errores y facilita busqueda, filtrado y operaciones.
Formato recomendado:
<env>-<service>-<resource>-<metric>-<severity>
Ejemplos:
stg-ec2-bastion-cpu-warningstg-ec2-api-statuscheckfailed-critical
3) Separar canales de notificación por entorno
No mezcles en un mismo topic alertas de dev, staging y prod.
Beneficios:
- menos ruido
- troubleshooting más rápido
- validaciones de rollout más seguras
Patrón habitual:
dev-infra-alertsstg-infra-alertsprod-infra-alerts
4) Diseñar pensando en rollout por entornos
Un error frecuente es intentar llegar a producción demasiado pronto.
Patrón recomendado:
dev: validar recurso, naming y canal SNSstaging: validar repetibilidad por Terraformprod: aplicar configuración ya estabilizada
Este enfoque reduce riesgo y evita “sorpresas de IaC” en el entorno más sensible.
Decisiones de modelado en Terraform
Root module vs módulo dedicado de monitorización
Aunque puedes declarar alarmas en el root module, un módulo dedicado suele escalar mejor cuando el sistema crece.
Ventajas del módulo de monitorización:
- Encapsula SNS + alarmas.
- Reutilizable por entorno.
- Fácil de extender a nuevas métricas/servicios.
- Mantiene el root como orquestador.
Patrón práctico:
modules/monitoring_ec2_alerts- root pasa IDs/nombres necesarios (instancia, ASG, endpoint de notificación)
Variables de Terraform vs variables de entorno
Una confusión habitual en Terraform Cloud es mezclar:
- Terraform variables (inputs declarados en el código)
- Environment variables (credenciales y configuración del runtime)
Regla simple:
infra_alerts_email-> Terraform variableAWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY,AWS_DEFAULT_REGION-> Environment variables
Separarlo bien reduce warnings y evita configuraciones ambiguas.
Trade-offs reales que conviene decidir antes
Alarmas por InstanceId vs por AutoScalingGroupName
No hay una respuesta universal. Depende de tu objetivo operativo.
Por InstanceId
- más granular
- ideal para bastion o instancias fijas
- menos robusto si hay reemplazos frecuentes
Por AutoScalingGroupName
- más estable para APIs detras de ASG
- mejor para continuidad del despliegue
- menos granular si escalan varias instancias
Diseñar este punto antes evita refactors innecesarios.
Qué validar primero
No intentes validar todas las métricas el mismo día.
Secuencia recomendada:
- SNS + suscripción
- una alarma simple (ej. CPU warning)
- prueba controlada
- resto del baseline
Flujo operativo seguro (PR -> plan -> apply)
Un flujo simple y robusto para alertas IaC:
- Crear rama por issue.
- Implementar cambios (módulo, variables, naming, outputs).
terraform validate.terraform plany revisar diff.- Aplicar solo cuando el plan es entendible y acotado.
- Verificar recursos en AWS + test de notificación.
El punto clave no es solo “que Terraform aplique”. Es que el equipo pueda entender el cambio antes de aplicarlo.
Checklist de diseño antes de implementar
- Naming estándar definido por entorno
- Canales SNS separados por entorno
- Lista mínima de alertas (baseline) acordada
- Estrategia de rollout
dev -> staging -> prod - Decisión tomada:
InstanceIdvsASG - Variables/credenciales separadas correctamente en Terraform Cloud
- Plan de validación operativa (incluye prueba real)
Relación con un enfoque manual (consola/CLI)
IaC no sustituye el aprendizaje del flujo nativo de AWS. Lo complementa.
Si quieres entender primero CloudWatch y SNS desde consola/CLI con una prueba real de CPU, revisa este post previo:
Ese enfoque es ideal para aprender. Este post es ideal para diseñar y escalar.
Cierre
Diseñar alertas preventivas como IaC no va solo de “automatizar Terraform”. Va de construir un sistema operable: con rollout seguro, naming consistente, canales por entorno y cambios revisables.
Cuando esa base esta bien planteada, la implementación técnica es mucho más sencilla de mantener.
Siguiente paso recomendado: implementa el baseline con Terraform usando SNS + CloudWatch y valida el flujo end-to-end. Para eso, aquí tienes la guía práctica: Implementar alarmas de infraestructura con Terraform en AWS (SNS + CloudWatch) paso a paso.
¿Impulsamos tu plan FinOps?
Si quieres pasar de recomendaciones a resultados, puedo ayudarte a priorizar quick wins, owners y métricas de seguimiento semanales.